1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| import requests
from bs4 import BeautifulSoup
import pandas as pd
cookie = '自己bp抓包填一下啦'
headers = {
'Host': 'www.butian.net',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'Cookie':cookie,
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',
'Origin': 'https://www.butian.net',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
butian=requests.post('https://www.butian.net/Reward/pub', headers=headers) #post方式访问返回josn
pages=int(butian.json()['data']['count']) #提取josn中count参数 为补天公益页数
print('获取公益SRC厂商列表页数:' ,pages ,'页')
p=0
company_id = []
company_name = []
company_url = []
while p < pages :
p += 1
data = {'s': 1, 'p': p, 'token': ''}
butian = requests.post('https://www.butian.net/Reward/pub', headers=headers,data=data)
list = butian.json()['data']['list']
for item in list:
company_id.append(item['company_id']) #item遍历company_id 写入company_id列表
company_name.append(item['company_name'])
print('第' ,p,'页厂商名字与ID获取成功')
print('共获取到', len(company_id),'个公益厂商')
for i in range(len(company_id)):
params = {'cid': company_id[i]}
url = requests.get('https://www.butian.net/Loo/submit',headers=headers,params=params)
html=BeautifulSoup(url.text, 'lxml')
url = html.find(name='input', attrs={'name': 'host'}).attrs['value']
company_url.append(url)
print('正在获取厂商ID', company_id[i], '的URL,还剩',len(company_id)-(i+1),'个厂商未获取')
#print(company_id)
#print(company_name)
#print(company_url)
#这里为列 选用pandas
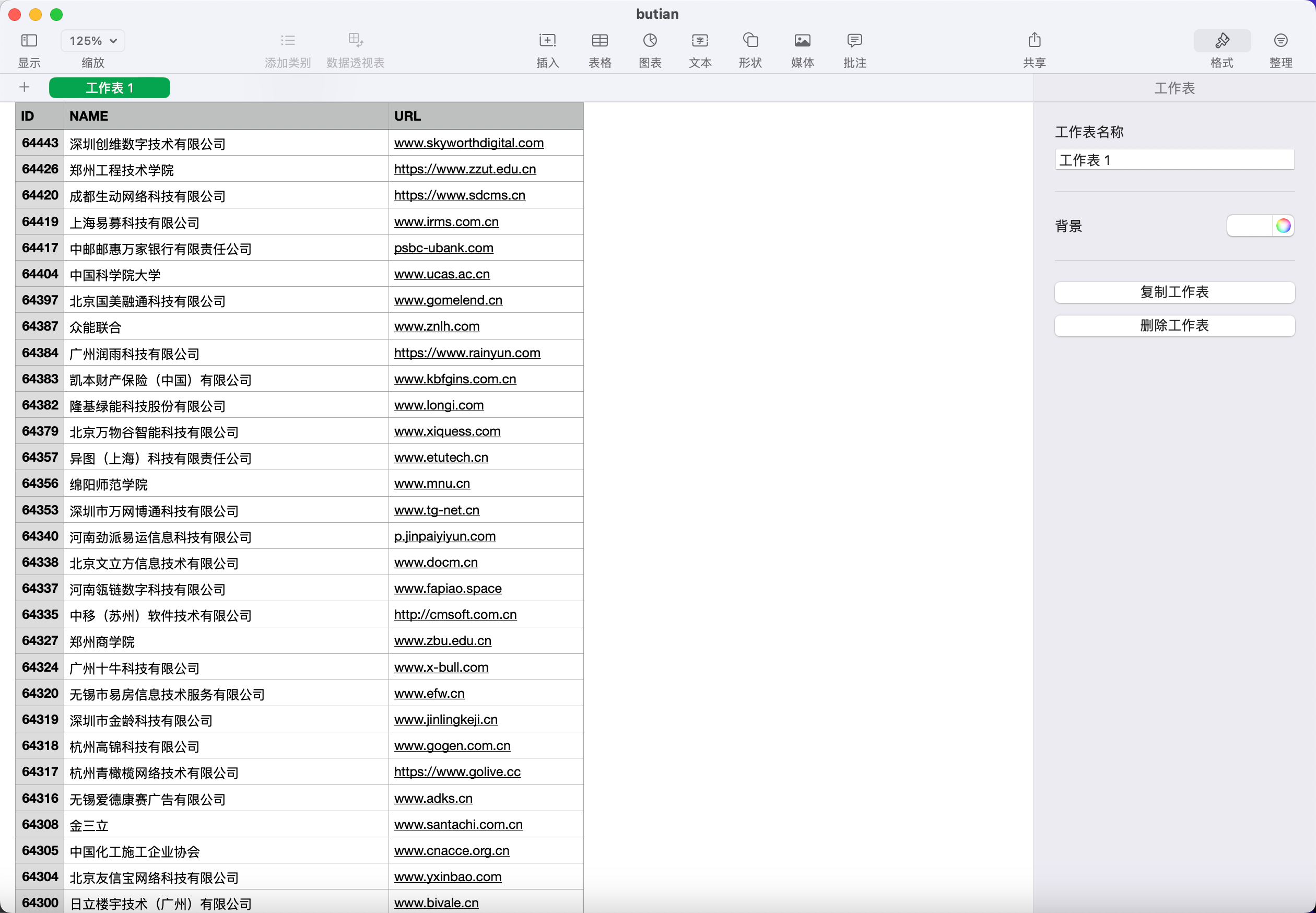
butian= pd.DataFrame({'ID':company_id,'NAME':company_name,'URL':company_url})
butian.to_csv("butian.csv",index=False)
|